| 基于规则的摔倒检测系统 | 语言及主要控件:C# + Emgu.CV 3.1 |
下载 download |
通过Kinect v1.0摄像头,实时捕获人体关节数据,并通过规则定义摔倒行为的主要特点,逐帧追踪并分析深度视频,并得出判定结论。

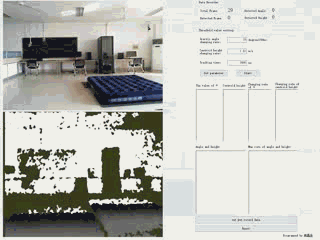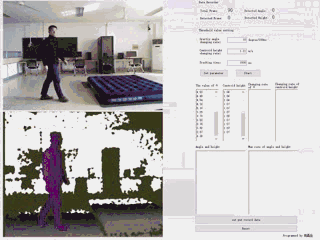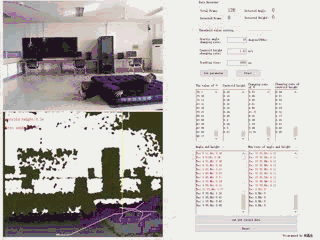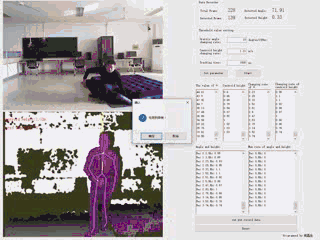
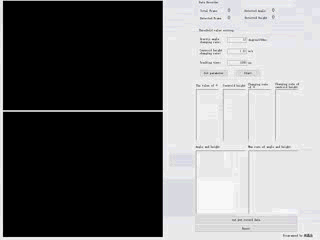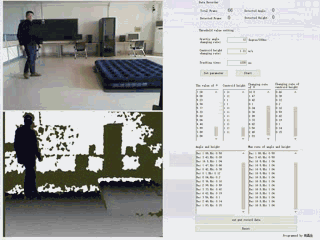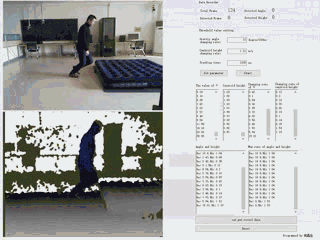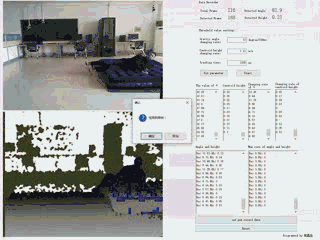

| 基于规则的摔倒检测系统 | 语言及主要控件:C# + Emgu.CV 3.1 |
下载 download |
| 基于规则的坐姿检测系统 | 语言及主要控件:C# + Emgu.CV 3.1 |
下载 download |
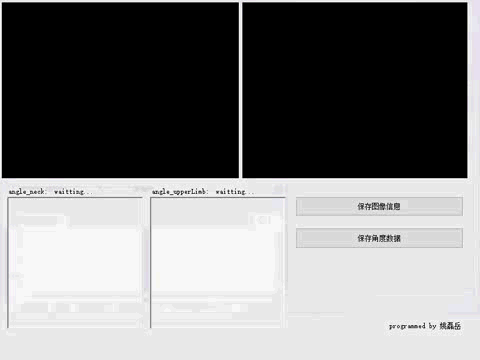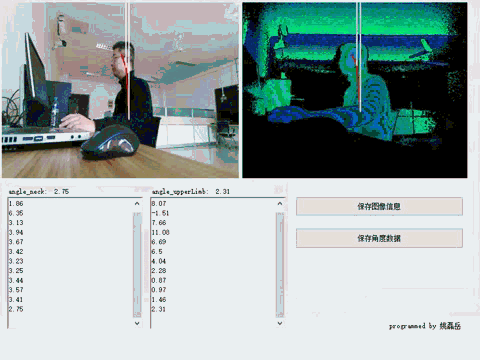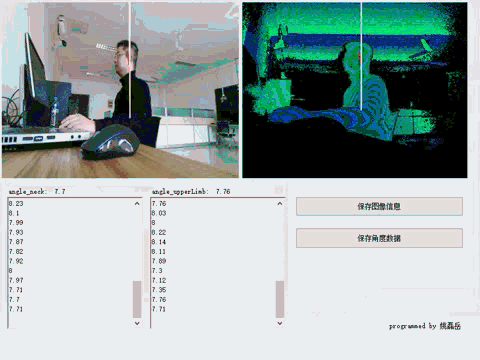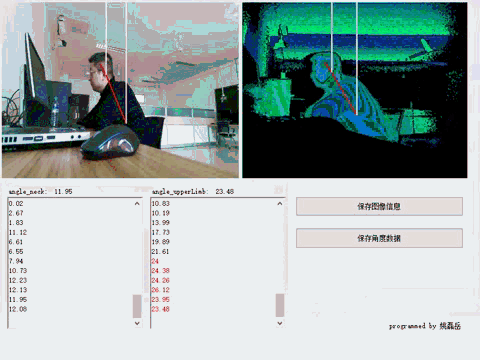 通过Kinect v2.0摄像头,实时捕获人体关节数据,并通过规则定义标准坐姿行为,
在一段时间内(10分钟)逐帧追踪并分析深度视频,并得出判定结论。
通过Kinect v2.0摄像头,实时捕获人体关节数据,并通过规则定义标准坐姿行为,
在一段时间内(10分钟)逐帧追踪并分析深度视频,并得出判定结论。| 基于关节点位置的紧凑型运动图谱(DJMI)的生成 | 语言及主要控件:C# |
下载 download |
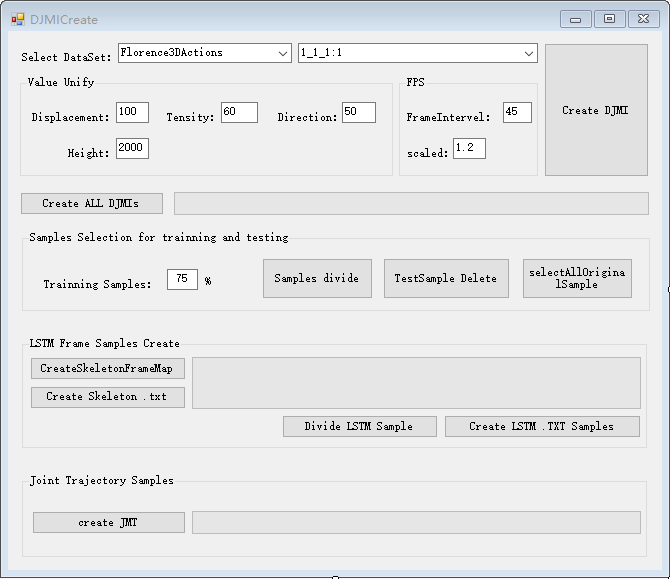
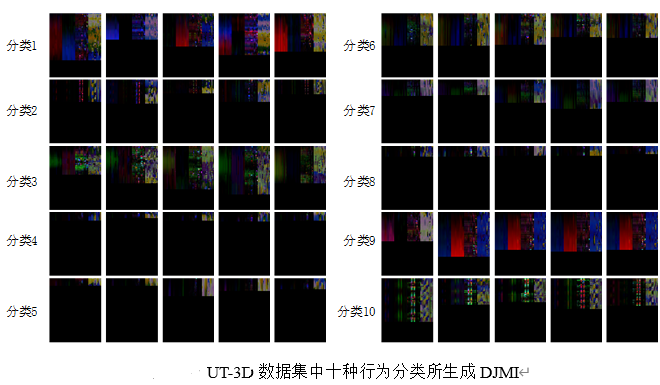
| 基于DJMI的动作识别模型 | 语言及主要控件:Python + TensorFlow gpu-2.3 |
下载 download |
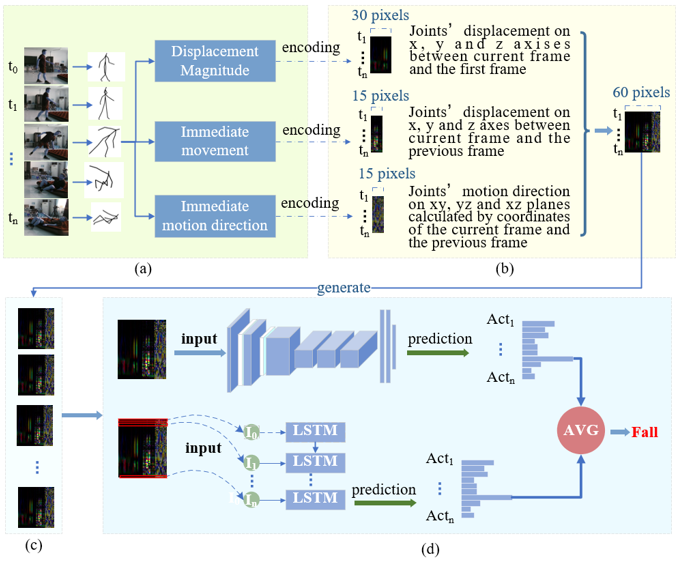
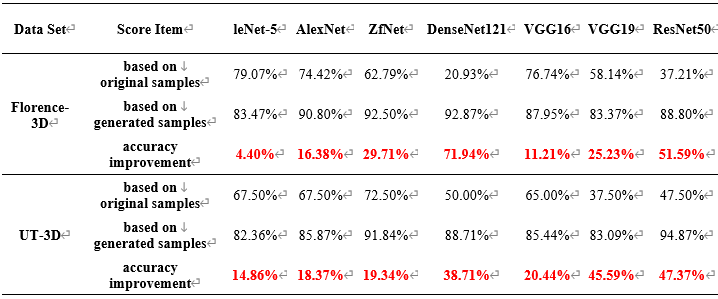
| “可信”样本生成与可视化系统 | 语言及主要控件:C# + Emgu.CV |
下载 download |
| 多尺度卷积神经网络动作识别模型 | 语言及主要控件:Python + TensorFlow gpu-2.3 |
下载 download |
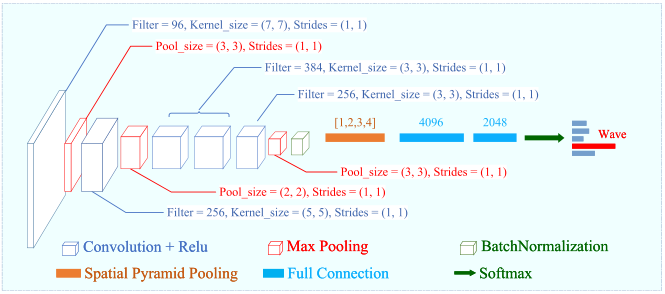
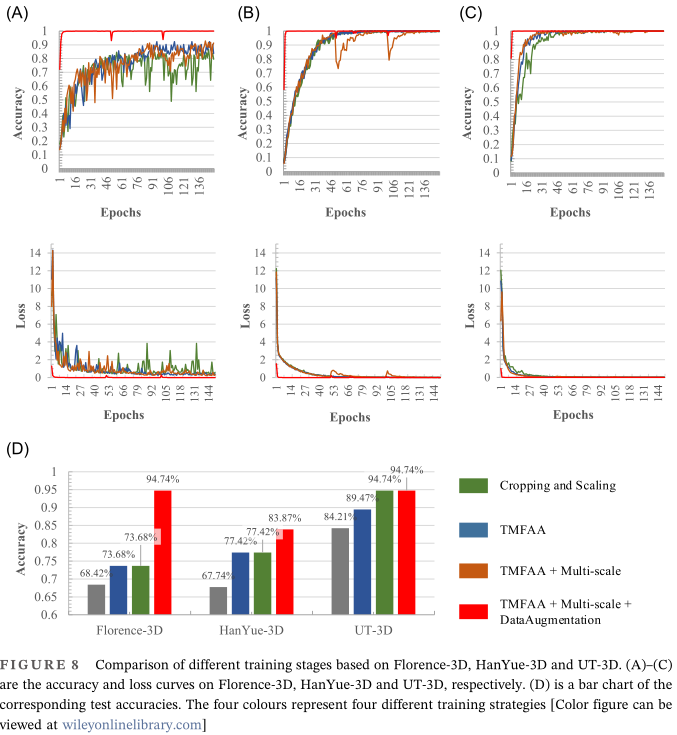
| 基于LSF-TD的动作时序定位模型 | 语言及主要控件:Python + TensorFlow gpu-2.3 |
下载 download |
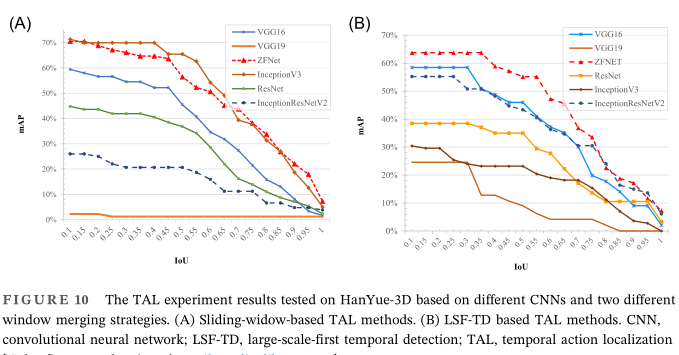
| 基于语义定义的复杂行为样本增强 | 语言及主要控件:c# |
下载 download |
| 基于语义定义的复杂行为识别模型 | 语言及主要控件:Python + TensorFlow gpu-2.3 |
下载 download |
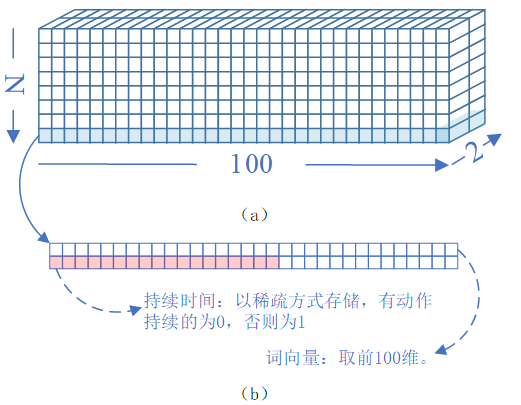
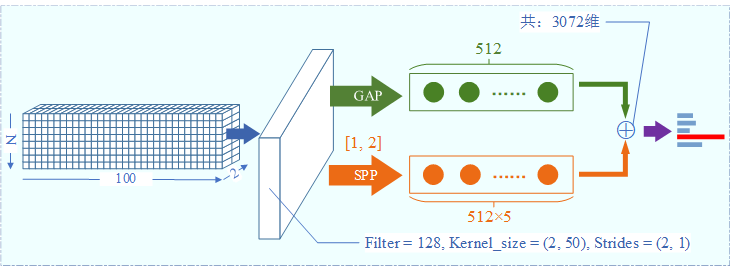
| 零样本情况下语义学习与识别测试 | 语言及主要控件:Python + TensorFlow gpu-2.3 |
下载 download |

